


The Next Steps: Dust To Digital
FYI #001: How we'll digitally archive newspapers and make Nigerian history digitally available to anyone, anywhere.

Every day since 1964, a librarian somewhere in Nigeria has shown up at work, dutifully collected the daily newspaper bound and stored them. Those bounds are labelled by the publisher, month and year. That seemingly mundane task is their contribution to the intellectual memory of a country, and perhaps a continent.
A lot has changed since this process began.

Libraries have struggled with the funding and resources to properly manage their archives. Let’s say you want to find a newspaper from the day you were born. First, you’ll need to figure out which national library holds the newspaper, then you’ll need a full day to visit their archives and dig through to find it. If you are lucky to eventually find it, it’ll most likely be loosely bound, with the newsprint falling apart.
Information is poorly preserved, inaccessible and disorganised. It shouldn’t be this way.
We have an opportunity to build on the painstaking work of the librarians and breathe new life into old newspapers. We can access history, explore data, reclaim identity, and connect with our history.
The demand for this information is immense. Since announcing this project, over 100 people have volunteered to participate in varying degrees, from funding to volunteering skills. We don’t take that lightly at all.
This post will give you a sense of everything that’s happened in the past month, and it won’t be the last of its kind.
There are three problems to tackle.
When we asked the question “is it possible to find a newspaper from every day in Nigerian history”, we had a sample period in mind. We chose January 1st, 1960 to December 31st, 2010. That question was answered when we found about 95% of the days in about five weeks.
The next important question – which is also the next problem – is how do we gain access?
How do you convince a library to give you prolonged access to their libraries because you need to scan over 18,000 newspapers and more than 500,000 stories?
The good news is, you can ask and pray. Even better, someone else already did.
Amanda Kirby runs the privately funded Joliba Africa, where she’s spent the better part of the last decade painstakingly collecting old documents, including newspapers and photos.

This effort is why the National Archives of Nigeria has granted her access, giving her permission to digitally archive everything. “Every access I have,” Amanda told me, “you have.” This is a big deal.
There are intellectual property questions and a dozen newspapers to convince that making their old newspapers available is a net positive.
Over the coming weeks, we’ll be speaking IP experts here, including people who already volunteered.
Scanning looks like an easy problem to solve.
Until you realise that the average commercial scanner will capture the dimensions of A3 paper at most. An open spread newspaper reaches up to A2 and over.
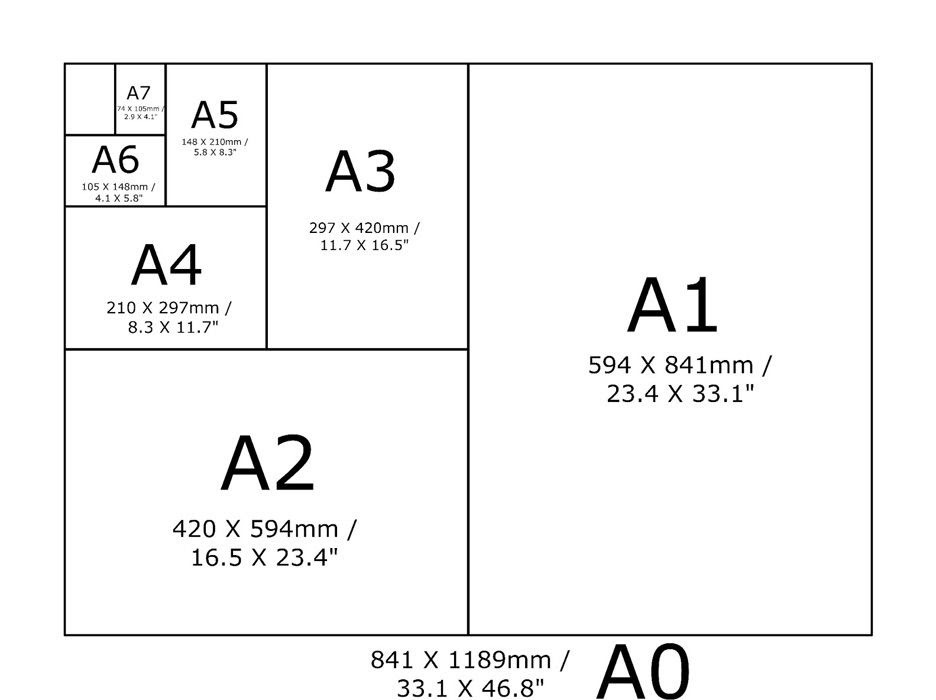
Archived newspapers are case bound, so folding is impossible. Even if it were, they’d be too fragile to treat that way.
The perfect printer is the overhead type, where you’d just need to place the casebound newspapers on a surface and flip the pages. We found one printer that’s efficient enough to scan an entire newspaper in less than 10 minutes. Since it’s a large format scanner, the price also appears to be, well, large format.
The Bookeye Scanner is one of the popular choices for scholars like Abdulbasit.


It costs up to $17,000 and because we want to archive in perpetuity, this is a valuable investment for time and efficiency. We will also be making the scanner available to anyone, who is looking to digitize an archive of any kind.
We can’t afford a Bookeye Scanner yet, but we can afford a digital camera set up. This can capture images of the right dimension and quality but at a painfully slow pace. In the short term, it’s worth experimenting with a setup that shows you what we’re trying to achieve at a small scale.
How can you make the information in scanned images searchable?
It’s not enough to scan old newspapers into images and make them available online. We need to make the information in them discoverable. Optical Character Recognition (OCR) will help us extract the text in these scanned images, making them searchable. Your smartphone is capable of this task on a small scale.
Newspapers tend to have tricky layouts – images, cartoons, article boundaries, ads – and it’s going to require some advanced skills to separate what is being OCR’d.
We’re going to work with open-source solutions that currently exist, and build on top of that for our peculiar struggles.
While we’re figuring out how to extract the information from over 5 decades of newspapers, we’re going to need a home for all this information when we eventually extract them.
The Digital Archives.
The digital archives we build must be open, accessible, organised, and sustained by the support from its users.
This will require a lot of research, writing, design, code and documentation. We’ll build.
This is where you come in.
If you’re reading this, there’s a good chance you’ve already volunteered to support this project. We cannot overstate how grateful we are. The only reason you haven’t heard from me personally is that we’re trying to take this one step at a time.
If you have not volunteered but want to, here you go:
Everyone is welcome because eventually, everyone will have a brick to lift. Or two.
We also need money. Lots of it. We need to buy the scanner, build the website, pay for subscriptions, host the images and pay for the logistics of moving people and equipment from library to library so that we can scan the archives. We’d tell you exactly how much we need, but it might scare you off. However, you know where a good place to start is? $25,000.
We can buy equipment, like that nice printer to help speed things up. We can pay the people who’ll show up every single day and scan.
If you’d like to donate immediately, so you don’t forget, do it here:
₦1,000 is a step in the right direction for us, but so is ₦10,000, or ₦100,000. Or ₦1 million. We already keep the open spreadsheet here, so you always know where your money is going.
If you know someone we should be talking to, holler.
Here’s how we’ll be accountable to you:
As we embark on this project, we are going to rely heavily on volunteers and donors. The support we’ve received already has been overwhelming. It leaves us feeling grateful, but also an immense sense of responsibility. In order to build a digital archive that is truly open, we’ve decided that the process itself should be open.
In the public library spirit, we’re going to keep as much information as we can open. We’ll register a non-profit. We’ll keep the financial spreadsheets open. We’ll keep the roadmap open, and we’re going to keep progress open. That’s why this substack exists; so we can keep an open log of questions we’ve found answers to and stay accountable.
By the next update, everyone will:
Receive updates on the progress with the scanning experiment, and the next steps for archiving.
Get a clear sense of what we’re trying to build with the Digital Archives, which volunteers will be working on it, and what the timelines are.
You’ll be able to track the progress on goals with our updates.
When a newspaper deteriorates completely, everything in it dies with it. We cannot let this happen. The work we do is how the dying ends. Donate. Volunteer. And if you have any questions, hit me up.
P.S: Your trivia for the day is about President Shehu Shagari’s 1984 budget. He actually gave it a name, calling it the “Budget of Re-dedication”. This National Concord story has some of the numbers.

This would actually be an amazing startup. Especially if you could scale this to every company in the world. I would legit pay a > $50 for a digital database of newspapers over the last 50 years OCRs and searchable. Are you sure you shouldn't be doing this as a startup rather than as an NGO or charity. Let me know if you want to talk about building this into a self sustaining business.